

A critical review of the machine learning guided design of metallic glasses for superior glass-forming ability


Abstract
The discovery of novel metallic glasses (MGs) with high glass-forming ability (GFA) has been an important area of active research for years in materials science and engineering. Unfortunately, the traditional approach based on trial-and-error methods is inefficient, time consuming and costly. Therefore, machine learning (ML) has recently drawn significant research interest as an alternative approach for the development of MGs. In this review, we discuss the current progress regarding the ML guided design of MGs from a variety of perspectives, including the GFA database, data representation, ML algorithms and numerical evaluation. Furthermore, we consider the challenges facing this field, including the scarcity and quality of GFA data, the development of physics informed data descriptors, the selection of appropriate algorithms and the necessity for experimental validation. We also briefly discuss possible solutions to tackle these challenges.
Keywords
INTRODUCTION
Since their first discovery in the 1960s[1], metallic glasses (MGs) have attracted extensive research attention because of their excellent properties, which include strong resilience[2], high strength[3], excellent hardness[3] and corrosion resistance[4] and good biocompatibility[5]. Unfortunately, due to their relatively poor glass-forming ability (GFA), as-cast MGs can only attain a limited size, which restricts their development and application in various industrial sectors. Until now, the conventional design of MGs has been mainly based on trial-and-error methods with guidance from empirical rules[6]. However, this approach is well known to be inefficient with regards to time and cost. Thus, the development of new approaches for the design of MGs, particularly chemically complexed MGs with good GFA and properties, remains an open issue for the MG community.
The past decade has witnessed significant developments in data science and machine learning (ML). ML is a data-driven approach that has been proved to be considerably effective in addressing complicated problems[7]. Given that the design of MGs always has a target property, supervised learning, which has been well developed to seek the correlation between input descriptors and output labels, is the most preferred approach in ML modeling for MG design. To date, researchers have already built different supervised learning-based ML models to address various problems related to MG design, such as the GFA of alloys[8-27], GFA-related characteristic temperatures[13,14,19,20,23,25,28,29] and various other mechanical and magnetic properties[19,22,30]. With the hitherto reported data, one can design data descriptors based on compositional information, empirical parameters or physical theories. One can then apply classification and/or regression algorithms to train a ML model, which can be further used to guide the new MG discovery. A number of new MG compositions have been developed so far through ML[20,23,31]. These ML efforts are therefore highly promising for the acceleration of MG development.
Figure 1 illustrates two different approaches to the design of new MGs. As shown in Figure 1A, the conventional approach is in essence a trial-and-error method, which starts with compositional design based on either empirical rules or physical models and then proceeds to process selection and structural and property characterization. If the properties of the designed MG do not meet the need or requirements, the data are usually considered useless (or “bad” data) and are hence discarded. The same process can be repeated many times until the target properties are achieved, which produces “good” data but is usually time consuming and highly dependent on human skills and experience. In contrast, a typical data driven approach [Figure 1B] comprises three steps, i.e., data representation, ML modeling and experimental validation. In this case, both “bad” and “good” data with properly designed features (or descriptors) and labels are required to build up a database (or dataset). Afterward, one can train and develop a ML model based on these data that will be used subsequently for experimental validation. Compared to the conventional approach, the data driven (or ML-based) approach is less dependent on human factors, much more efficient and cost effective.

Figure 1. Schematics of (A) a conventional approach and (B) a data driven approach for the design of MGs. MGs: Metallic glasses.
Nevertheless, we note that it is not straightforward to build a predictable ML model for MG design and there are several issues that must be considered. The first issue is that the dataset of MG is not large. Only thousands of MG compositions have been reported in the past 60 years and most still lack detailed property information. For example, the number of Vickers hardness data is fewer than 100, which is not adequate for ML modeling. Although one might develop physics-based descriptors for a small dataset for an enhanced ML performance[32], the current literature regarding ML guided MG design is still overwhelmed by empirical data descriptors. Furthermore, overfitting is another issue and needs to be addressed for effective ML modeling[7]. Considering the rapid development in this field, we provide a focused review on the recent ML guided MG design here. In particular, we discuss two general issues: (1) how ML models have been built; and (2) how ML validation and further ML prediction have been achieved.
GFA DATA
In principle, both data quantity and quality are important for ML modeling. As shown in Table 1, the majority of GFA data used for ML modeling are from prior experiments reported in the literature[23], while only a few from atomistic simulations. According to Zhou et al.[31], the available GFA dataset covers a wide range of MG compositions. As seen in Figure 2, the principal elements contained in the MG dataset include Fe, Zr, Ni, Al, Co, Mg, Cu, La, Pd and many others, as ranked according to the percentage of MGs based on them. Despite the seemingly compositional diversity, we note that MG compositions mainly encompass transition metals (e.g., Zr, Fe, Ni and Cu), alkaline-earth metals (e.g., Mg, Ca and Be), rare earth metals (e.g., La) and other metals (e.g., Al), as shown by the inset of Figure 2.

Figure 2. Comparison of various MGs based on their percentage in reported MG compositions. The inset highlights the number of times that an element is counted in all MG compositions reported so far. MGs: Metallic glasses.
Comparison of recent works on the ML guided design of MGs
GFA data can come from handbooks, such as Phase Diagrams and Physical Properties of Nonequilibrium Alloys[35] and Nonequilibrium Phase Diagrams of Ternary Amorphous Alloys[36]. In particular, it is noteworthy that that one may retrieve the GFA data directly from studies, such as Lu et al.[37] in 2002,
Although one may easily retrieve GFA data from prior works, data pre-screening and/or data transformation in order to rule out low-fidelity data usually needs to be performed. While this process of data pre-processing can be vital for ML modeling, particularly for a limited data size, we note that it has often been neglected in previous studies[14,15,18,42]. As noted by Liu et al.[24] and Zhou et al.[31], a GFA dataset built from successful experiments can be significantly biased if it only includes the data for good glass-forming alloys, thereby potentially compromising the efficiency of either classification or regression ML models.
To mitigate this problem, one can create a more balanced dataset by data undersampling[24] or oversampling[31], which is particularly useful for classification ML modeling. In addition, one can perform data transformation such that the distribution of the transformed data becomes closer to a normal distribution than before. In practice, this could improve the performance of regression ML models built upon the data of high skewness[31], such as those reported in Refs.[37,43]. Here, we note that Deng et al.[16] reported that improper data transformation may also jeopardize the performance of a ML model. Given the difference in the datasets used in prior works, these reports imply that one must carefully examine the structure of datasets relevant to the physical problem (e.g., range, skewness and so on) before choosing an appropriate method for data pre-processing. While the quality of the GFA data can be compromised by the traditional design of experiments, such as the use of the casting mold size to approximate the critical glass-forming size, which unavoidably leads to round up errors, human factors are additional issues that can cause data inconsistency. It is not uncommon to find reported data for the same alloy from different groups that appear different. Thus, additional efforts are needed in order to obtain high-fidelity data. One possible route is through high-throughput combinatorial experiments[40] and the other is through atomistic simulations[12].
DATA REPRESENTATION: DESCRIPTORS AND LABELS
After sufficient data have been collected, proper descriptors and labels need to be developed for them. In theory, data descriptors provide expressive information that can be linked to data labels[44]. Therefore, the design of suitable data descriptors is important for successful ML modeling[7,23,31]. As shown in Table 1, the current design of data descriptors is mostly based on alloy compositions and empirical rules. Although the compositional descriptors can be readily calculated once an alloy is known[13,17,29], they lack physical significance and require other types of complementary descriptors[8,13,26]. Therefore, by following the empirical rules[6,45,46], researchers can translate compositional information into data descriptors in order to enhance the performance of ML modeling. These empirical descriptors could include mean atomic size[20-22,47], atomic size difference[16,21,24,47], mixing enthalpy[20-22,47], ideal mixing entropy[20-22,24,47], mean electronegativity[16,20,22,47], electronegativity difference[24,47] and mean valence electron concentration[20,22,24,47].
According to Ward et al.[23], the number of compositional and empirical descriptors derived from the constituent elements could amount to 186, indicating that the ML modeling of the GFA of MGs could have a very high dimension. However, this high dimension of data increases the computational cost and, most importantly, can degrade the performance of ML models[32,44]. In contrast, Zhou et al.[31] recently utilized eight physics guided data descriptors, which proved sufficient for the development of a reliable ML model. These eight descriptors were derived from the effects of atomic size misfit, correlated entropy and local chemical affinity, based on which one can draw the parallel coordinate plots (PCPs) for different types of MGs (e.g., Zr-, Cu- and La-based MGs). As shown in Figure 3A-F, it is evident that these eight physics guided descriptors are distributed within narrow “bands” for MGs that can form bulk glasses. In comparison, the similar “bands” in the PCPs appear wider for those that can only form glassy ribbons. This behavior is interesting, which suggests that the compositional space, as characterized by the physics guided data descriptors, is limited for bulk metallic glasses (BMGs) relative to that for glassy ribbons.

Figure 3. Parallel coordinate plots of eight physics guided data descriptors for (A) Zr BMGs, (B) Cu BMGs, (C) La BMGs, (D) Zr glassy ribbons, (E) Cu glassy ribbons and (F) La glassy ribbons. Reprinted from Ref.[31], copyright (2021), with permission from Springer Nature. BMGs: Bulk metallic glasses.
Although the origin of data descriptors can affect their dimension, one can optimize the dimension of data descriptors through unsupervised learning, such as the principal component analysis (PCA)[41]. In theory, PCA extracts the eigenvectors from the covariance matrix of the data with descriptors and only keeps those with the largest eigenvalues. In doing so, PCA can retain the most important information by keeping the descriptors with high coefficients of variation while discarding those with low coefficients of variance[24,26], as exemplified by Figure 4A. In addition, one can also calculate the Pearson’s correlation coefficient (PCC)[22,24,26,27] of data descriptors, which measures the linear correlation between any two descriptors, as shown in Figure 4B. In order to reduce the dimension of data descriptors, one usually keeps those with a high PCC magnitude (e.g., |PCC| > 0.8) and removes the rest. In addition to PCA and PCC, we note that the following descriptor selection algorithms, such as the sequential backward selector[11,48], the exhaustive feature selector[11,48] and the ReliefF algorithm[22,49], are also available, which have already proved effective in improving the performance of ML modeling[11,22,24,26,27,41]. With respect to data labeling, we note that data labels are usually taken directly from the targeted properties, such as GFA, elastic modulus and GFA-related characteristic temperatures, for regression ML modeling, as shown in Table 1. In comparison, researchers often apply binary labeling for classification ML modeling. For instance, the good data or typical MG compositions can be labeled as “1”, while the bad data or non-MGs can be labeled as “0” according to Refs.[8,20-27,33].

ML MODELING
Once the high-fidelity data have been properly represented, one can develop ML models based on the available ML algorithms. Figure 5A shows the variety of ML algorithms that have been applied in the design of MGs, which include support vector machines (SVMs)[8,18,19,21,26,27,31], artificial neural networks (ANNs)[13-15,18,20,21,24,28,29,31], k-nearest neighbors[21,27], neighborhood components analysis[34], decision trees[9,11,17,21,26,31], random forests (RFs)[10,12,16,21-23,25-27,31,33,42], fusion algorithms[27], linear regression[18,26], Gaussian process regress[21,31], least absolute shrinkage and selection operator[12], ridge regression[12] and symbolic regression. These algorithms can gage the effect of data descriptors by a parameter generated by the descriptors[22]. Among these ML algorithms, we note that some have shown good performance and high adaptability, and are therefore very popular, such as ANNs. The common practice is that one can test different algorithms to solve the same problem and choose the best performing one to guide the subsequent alloy design.

Figure 5. (A) Schematic of available ML algorithms applied in MG design. (B) Word cloud depiction of ML algorithms in (A). Note that the larger the font, the more frequent the corresponding algorithm has been used. ML: Machine learning; MG: metallic glass.
According to the current literature, we note that traditional supervised learning dominates the ML modeling of MG design. To the best of our knowledge, we are not aware of any unsupervised learning algorithms that have been directly for the design of MGs except for the reduction of data dimensions[22,24,26,27,41]. For the sake of comparison, Figure 5B shows the word cloud depiction of the aforementioned ML algorithms. The font size for each ML algorithm corresponds to the frequency of its use. Clearly, RFs, ANNs and SVMs are the first three most popular ML algorithms, which could be attributed to their good performance in both regression and classification ML modeling. In addition to traditional supervised learning, deep learning was recently utilized for the design of MGs[50], such as the convolutional neural network, which was able to identify good glass-forming compositions at a high testing accuracy of 96.3%. Meanwhile, one can apply the 2D pseudo-image feature space to extract domain knowledge based features automatically from a small dataset[50]. These novel ML techniques are useful for the design of new MGs with superior GFA.
In training a ML model, various problems, such as underfitting, overfitting or irreducible errors[7], may occur, leading to poor performance and predictability of the ML model. Therefore, it is necessary to evaluate or validate the model predictability with “unseen” data, i.e., the data not used for model training. Until now, the most commonly used validation methods have been hold-out validation[24] and k-fold cross-validation[22]. In addition, one can also use the root mean square error[20,24,31], the coefficient of determination (R2)[10,12,16,17,31,42] and the correlation coefficient (R)[14,15,18,20,22,23,25,28] to validate the predictability of a regression ML model. As we previously discussed, the quality of the available GFA data is adversely affected by experimental measurements (e.g., round-up error[31,51]) and the data distribution (e.g., high skewness[16,17,31]). Therefore, the performance of ML models built upon these data is not high. According to Refs.[10,16,17], the R2 value is ~0.7 for well-trained GFA regressors. Recently, Zhou et al.[31] managed to increase the R2 value to 0.8 after reducing the skewness of the GFA data. In contrast, if the data label is a GFA-related temperature (e.g., Tg, Tx and Tl), which is not heavily affected by either round-up errors or a highly skewed distribution, the R2 value can be as high as 0.94-0.99 for well-trained ML models[29,42].
Alternatively, the performance of a GFA classifier is gaged by its overall accuracy, which depends on data noise and diversity. According to the literature[21,23,24,31], the overall accuracy of a GFA classifier is ~80%-90%. Apart from that, the model precision and recall of a specific class[11,24] are another two metrics for the performance of a GFA classifier, which are characterized by the confusion matrix. Figure 6A shows the confusion matrix of a well-trained GFA classifier, which has the entry of 81.6% for the positive predictive value (PPV) for the precise prediction of MG, 88.8% for the true positive rate (TPR) for the recall of MG, 82.9% for the negative predictive value (NPV) for the precise prediction of non-MG and 73.1% for the true negative rate (TNR) for the recall of the non-MG class[24]. This behavior indicates that the GFA classifier is well trained with a good and balanced performance. In addition, the receiver operating characteristic (ROC) curve, as shown in Figure 6B, is another performance indicator for a GFA classifier. We note that the ROC curve simply connects the origin (0, 0) and (1, 1) as a straight line for a dummy classifier (i.e., random guessing) and the value for the area under curve (AUC) is 0.5. In contrast, the ROC curve for a best performing classifier would bend rapidly toward TPR = 1 with AUC = 1[24]. In practice, the AUC value is ~0.94-0.95[24,31] for a well-trained GFA classifier. These numeric metrics provide the results of the immediate evaluation of the predictability of the ML models after data training. Based on the current literature, it appears that the ML models, particularly the GFA classifiers[8,20,22-24,27,31,33], exhibit a very good performance according to the results of numerical evaluation.
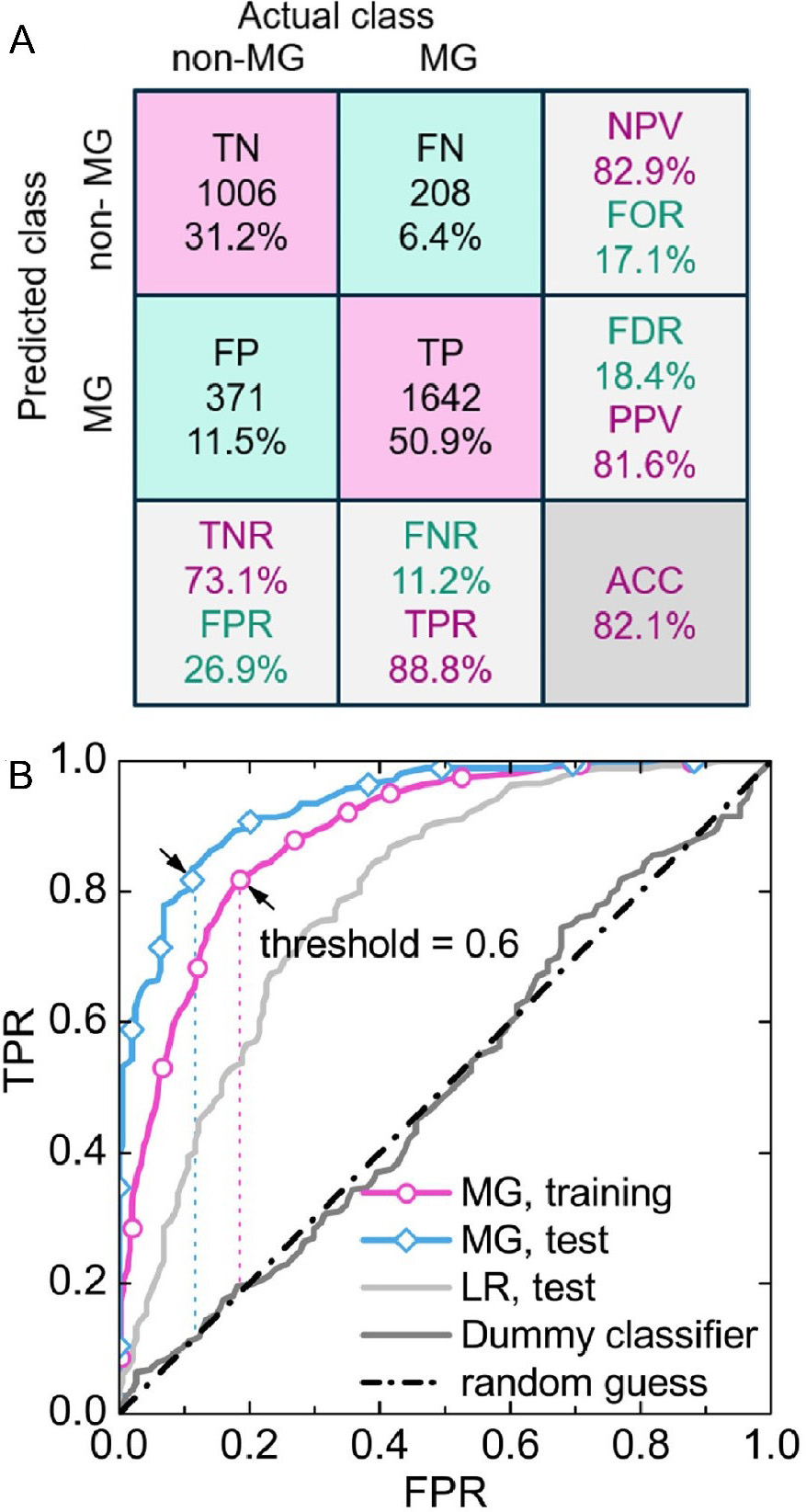
Figure 6. (A) Confusion matrix and (B) ROC curves for a classification ML model for MG formation. Note that the terminology and derivations in (A) are true negative (TN), false negative (FN), false positive (FP), true positive (TP), negative predictive value (NPV = TN/(TN + FN), false omission rate [FOR = FN/(TN + FN)], false discovery rate [FDR = FP/(FP + TP)], positive predictive value [PPV = TP/(TP + FP)], true negative rate [TNR = TN/(TN + FP)], false positive rate [FPR = FP/(FP + TN)], false negative rate [FNR = FN(TP + FN)], true positive rate [TPR = TP/(TP + FN)] and accuracy [ACC = (TP+TN)/(TP + TN + FP + FN)]. Reprinted from Ref.[24], copyright (2020), with permission from Elsevier. ROC: Receiver operating characteristic; ML: machine learning; MG: metallic glass.
EXPERIMENTAL VALIDATION
Although numerical validation provides the first and immediate assessment of the ML modeling, we stress that it is necessary to further evaluate the predictability of a ML model with experiments. In a recent work by Zhou et al.[31], the authors tested two ML models, the Levenberg-Marquardt backpropagation artificial neural network model (LMANN) and the ration quadratic kernel-based Gaussian process regression model (RQGPR) for the design of MGs. Interestingly, while these two ML models exhibit a similar value of R2 (~0.8) in numerical validation, they made noticeably different predictions with respect to the experimental data obtained from the Zr-Cu-(Ag, Al) quasi-ternary BMGs[52], which were not included in the original database for the ML models [Figure 7]. As seen in Figure 7A and B, it is clear that the predictions of the RQGPR model fit well with the experiments, while those of the LMANN model are clearly off from the experimental data [Figure 7B], which simply contradicts the results of numerical validation. Unfortunately, we note that only a few ML models were validated by experiments[9,19,20,23-26,28,29,42], so far and it is still not a mandate to carry out experimental validation on ML modeling. One possible reason for the disparity between theory and experiment may be due to the relative scarcity of high-fidelity experimental GFA data, which amount to only several hundred should the data of glassy ribbons be excluded. Therefore, as a new MG was designed, it could be out of the original design space spanned by the available MGs. In such a case, we would suggest that the adaptability and reliability of any future ML models should be tested both numerically and experimentally.

Figure 7. Comparison of GFA predictions from (A) RQGPR and (B) LMANN models with the experimental results obtained from the quasi-ternary Zr-Cu-(Ag, Al) system by Inoue et al.[52]. Reprinted from Ref.[31], copyright (2021), with permission from Springer Nature. GFA: Glass-forming ability; RQGPR: ration quadratic kernel-based Gaussian process regression; LMANN: Levenberg-Marquardt backpropagation artificial neural network.
Finally, we discuss the new MGs that were designed based on the ML models. According to the literature, Ward et al.[23] developed six Zr-based BMGs, Liu et al.[24] developed a series of glassy ribbons in the Ti-Fe-Cu and Ti-Ni-Zr ternary systems, Zhou et al.[31] developed six Zr-based BMGs and six high entropy glassy ribbons and Samavatian et al.[20] developed four Zr-based BMGs. First of all, it is clear that most of the newly designed MGs are concentrated on one specific type, i.e., Zr-based MGs, and it is not known yet whether these ML models can be extended to other types of MGs. To reveal the relation of some new MGs with the GFA dataset, we plot the distribution of the GFA dataset together with some new MGs by applying PCA to all data with the physics guided data descriptors provided by Zhou et al.[31]. As shown in Figure 8, it is obvious that the newly designed MG compositions just fall into the area covered by the GFA dataset. In other words, the accelerated search of new MGs could be effective only within the compositional space spanned by the existing data. Therefore, should more interesting or unusual MGs be discovered in future, we would require more high-fidelity data to expand the compositional space, resulting in the need for more extensive research into data generation via a high-throughput means.

Figure 8. Data visualization of GFA dataset (875 data) and newly designed MGs reported by Zhou et al.[31] through PCA. Note that PC1 stands for the first principal component while PC2 represents the second. GFA: Glass-forming ability; MGs: metallic glasses; PCA: principal component analysis.
SUMMARY
We have provided a critical review on the recent progress in the ML guided MG design for superior GFA. Compared to the traditional trial-and-error approach, the data-driven approach is powerful in that it can significantly accelerate the discovery of new MGs. However, we are still facing challenges with respect to the development of a reliable and adaptive ML models because of the lack of sufficient high-fidelity GFA data across different types of MGs. In addition, we note that the development of data descriptors and the choice of ML algorithms are also important, which could affect the results of numerical and experimental validation. Finally, we also note that nearly all reported ML algorithms belong to supervised learning, which demands human interventions during model training and could be heavily influenced by human factors in exploring the multi-dimensional compositional space. Therefore, in the opinion of the current authors, it may be worthwhile to extend the current efforts to novel learning algorithms (e.g., deep learning/unsupervised learning), such that an automated design of MGs could become possible in future.
DECLARATIONS
Authors’ contributionsSupervised the project: Yang Y
Wrote the manuscript: Zhou Z, Shang Y, Yang Y
Availability of data and materialsNot applicable.
Financial support and sponsorshipYY acknowledges the financial support provided by Research Grants Committee (RGC), the Hong Kong government, through General Research Fund (GRF) with the grant numbers (CityU11200719, CityU11213118) and also by City University of Hong Kong through the internal grant with the grant number 7005438.
Conflicts of interestAll authors declared that there are no conflicts interest.
Ethical approval and consent to participateNot applicable.
Consent for publicationNot applicable.
Copyright© The Author(s) 2022.
REFERENCES
1. Klement W, Willens RH, Duwez P. Non-crystalline structure in solidified gold-silicon alloys. Nature 1960;187:869-70.
2. Wang WH. The elastic properties, elastic models and elastic perspectives of metallic glasses. Prog Mater Sci 2012;57:487-656.
4. Scully JR, Gebert A, Payer JH. Corrosion and related mechanical properties of bulk metallic glasses. J Mater Res 2006;22:302-13.
5. Sharma A, Zadorozhnyy V. Review of the recent development in metallic glass and its composites. Metals 2021;11:1933.
6. Inoue A. Stabilization of metallic supercooled liquid and bulk amorphous alloys. Acta Mater 2000;48:279-306.
7. Butler KT, Davies DW, Cartwright H, Isayev O, Walsh A. Machine learning for molecular and materials science. Nature 2018;559:547-55.
8. Sun YT, Bai HY, Li MZ, Wang WH. Machine learning approach for prediction and understanding of glass-forming ability. J Phys Chem Lett 2017;8:3434-9.
9. Dasgupta A, Broderick SR, Mack C, et al. Probabilistic assessment of glass forming ability rules for metallic glasses aided by automated analysis of phase diagrams. Sci Rep 2019;9:357.
10. Peng L, Long Z, Zhao M. Determination of glass forming ability of bulk metallic glasses based on machine learning. Comput Mater Sci 2021;195:110480.
11. Xiong J, Shi S, Zhang T. Machine learning prediction of glass-forming ability in bulk metallic glasses. Comput Mater Sci 2021;192:110362.
12. Afflerbach BT, Schultz L, Perepezko JH, Voyles PM, Szlufarska I, Morgan D. Molecular simulation-derived features for machine learning predictions of metal glass forming ability. Comput Mater Sci 2021;199:110728.
13. Keong K, Sha W, Malinov S. Artificial neural network modelling of crystallization temperatures of the Ni-P based amorphous alloys. Mater Sci Eng A 2004;365:212-8.
14. Cai A, Xiong X, Liu Y, An W, Tan J. Artificial neural network modeling of reduced glass transition temperature of glass forming alloys. Appl Phys Lett 2008;92:111909.
15. Cai AH, Liu Y, An WK, et al. Prediction of critical cooling rate for glass forming alloys by artificial neural network. Mater Des 2013;52:671-6.
16. Deng B, Zhang Y. Critical feature space for predicting the glass forming ability of metallic alloys revealed by machine learning. Chem Phys 2020;538:110898.
17. Mastropietro DG, Moya JA. Design of Fe-based bulk metallic glasses for maximum amorphous diameter (Dmax) using machine learning models. Comput Mater Sci 2021;188:110230.
18. Majid A, Ahsan SB, Tariq NUH. Modeling glass-forming ability of bulk metallic glasses using computational intelligent techniques. Appl Soft Comput J 2015;28:569-78.
19. Li J, Chen T, Zekiy AO. Correlative study between elastic modulus and glass formation in ZrCuAl(X) amorphous system using a machine learning approach. Appl Phys A 2021:127.
20. Samavatian M, Gholamipour R, Samavatian V. Discovery of novel quaternary bulk metallic glasses using a developed correlation-based neural network approach. Comput Mater Sci 2021;186:110025.
21. Xiong J, Zhang T, Shi S. Machine learning prediction of elastic properties and glass-forming ability of bulk metallic glasses. MRS Commun 2019;9:576-85.
22. Xiong J, Shi S, Zhang T. A machine-learning approach to predicting and understanding the properties of amorphous metallic alloys. Mater Des 2020;187:108378.
23. Ward L, O’keeffe SC, Stevick J, Jelbert GR, Aykol M, Wolverton C. A machine learning approach for engineering bulk metallic glass alloys. Acta Mater 2018;159:102-11.
24. Liu X, Li X, He Q, et al. Machine learning-based glass formation prediction in multicomponent alloys. Acta Mater 2020;201:182-90.
25. Chen T, Rajiman R, Elveny M, et al. Engineering of novel Fe-based bulk metallic glasses using a machine learning-based approach. Arab J Sci Eng 2021;46:12417-25.
26. Li Z, Long Z, Lei S, Zhang T, Liu X, Kuang D. Predicting the glass formation of metallic glasses using machine learning approaches. Comput Mater Sci 2021;197:110656.
27. Zhang Y, Xing G, Sha Z, Poh L. A two-step fused machine learning approach for the prediction of glass-forming ability of metallic glasses. J Alloys Compd 2021;875:160040.
28. Cai A, Xiong X, Liu Y, An W, Tan J, Luo Y. Artificial neural network modeling for undercooled liquid region of glass forming alloys. Comput Mater Sci 2010;48:109-14.
29. Jeon J, Seo N, Kim H, et al. Inverse design of Fe-based bulk metallic glasses using machine learning. Metals 2021;11:729.
30. Xiong J, Shi S, Zhang T. Machine learning of phases and mechanical properties in complex concentrated alloys. J Mater Sci Technol 2021;87:133-42.
31. Zhou ZQ, He QF, Liu XD, et al. Rational design of chemically complex metallic glasses by hybrid modeling guided machine learning. npj Comput Mater 2021;7:138.
32. Zhang Y, Ling C. A strategy to apply machine learning to small datasets in materials science. npj Comput Mater 2018;4:25.
33. Ren F, Ward L, Williams T, et al. Accelerated discovery of metallic glasses through iteration of machine learning and high-throughput experiments. Sci Adv 2018;4:eaaq1566.
34. Ren B, Long Z, Deng R. A new criterion for predicting the glass-forming ability of alloys based on machine learning. Comput Mater Sci 2021;189:110259.
35. Kawazoe Y, Carow-Watamura U, Louzguine DV. Phase diagrams and physical properties of nonequilibrium alloys. 1st ed. Berlin Heidelberg: Springer; 1997.
36. Kawazoe Y. Nonequilibrium phase diagrams of ternary amorphous alloys. Berlin Heidelberg: Springer; 1997.
37. Lu Z, Liu C. A new glass-forming ability criterion for bulk metallic glasses. Acta Mater 2002;50:3501-12.
38. Lu Z, Bei H, Liu C. Recent progress in quantifying glass-forming ability of bulk metallic glasses. Intermetallics 2007;15:618-24.
39. Long Z, Wei H, Ding Y, Zhang P, Xie G, Inoue A. A new criterion for predicting the glass-forming ability of bulk metallic glasses. J Alloys Compd 2009;475:207-19.
40. Guo S, Liu C. Phase stability in high entropy alloys: formation of solid-solution phase or amorphous phase. Prog Nat Sci Mater Int 2011;21:433-46.
41. Tripathi MK, Chattopadhyay P, Ganguly S. Multivariate analysis and classification of bulk metallic glasses using principal component analysis. Comput Mater Sci 2015;107:79-87.
42. Chen T, Yu S, Sajjadifar S. Engineering of new Mg-based glassy compositions by a computational intelligence model. Mater Lett 2021;290:129441.
43. Johnson WL, Na JH, Demetriou MD. Quantifying the origin of metallic glass formation. Nat Commun 2016;7:10313.
44. Ghiringhelli LM, Vybiral J, Levchenko SV, Draxl C, Scheffler M. Big data of materials science: critical role of the descriptor. Phys Rev Lett 2015;114:105503.
47. Zhou Z, Zhou Y, He Q, Ding Z, Li F, Yang Y. Machine learning guided appraisal and exploration of phase design for high entropy alloys. npj Comput Mater 2019;5:128.
48. Raschka S. MLxtend: providing machine learning and data science utilities and extensions to Python’s scientific computing stack. JOSS 2018;3:638.
49. Palma-mendoza R, Rodriguez D, de-Marcos L. Distributed ReliefF-based feature selection in Spark. Knowl Inf Syst 2018;57:1-20.
50. Feng S, Fu H, Zhou H, Wu Y, Lu Z, Dong H. A general and transferable deep learning framework for predicting phase formation in materials. npj Comput Mater 2021;7:10.
51. Suryanarayana C, Seki I, Inoue A. A critical analysis of the glass-forming ability of alloys. J Non Cryst Solids 2009;355:355-60.
Cite This Article

How to Cite
Zhou, Z.; Shang, Y.; Yang, Y. A critical review of the machine learning guided design of metallic glasses for superior glass-forming ability. J. Mater. Inf. 2022, 2, 2. http://dx.doi.org/10.20517/jmi.2021.12
Download Citation
Export Citation File:
Type of Import
Tips on Downloading Citation
Citation Manager File Format
Type of Import
Direct Import: When the Direct Import option is selected (the default state), a dialogue box will give you the option to Save or Open the downloaded citation data. Choosing Open will either launch your citation manager or give you a choice of applications with which to use the metadata. The Save option saves the file locally for later use.
Indirect Import: When the Indirect Import option is selected, the metadata is displayed and may be copied and pasted as needed.
About This Article
Copyright

Related

















Comments
Comments must be written in English. Spam, offensive content, impersonation, and private information will not be permitted. If any comment is reported and identified as inappropriate content by OAE staff, the comment will be removed without notice. If you have any queries or need any help, please contact us at support@oaepublish.com.